이런 합성곱은 인과적(causal)으로, 미래로부터의 어떠한 정보도 과거로 전달되지 않는다는 것을 의미한다.
즉, 모델은 시간 내에 진행되는 정보만 처리한다.
Causal : t시점의 예측 값에 대해 입력 변수는 t시점까지만 이용가능 Acausal : t시점의 예측 값에 대해 입력변수로 모든 시점의 입력값을 사용
TCN[시간 합성곱 네트워크]는 인과성(causality)으로 인해 RNN[순환 신경망]과는 달리 이전 시간 단계의 정보에 의존하지 않기 때문에 RNN의 문제를 가지고 있지 않는다.
또한 TCN는 RNN이 할 수 있는 것처럼 임의 길이의 입력 시퀀스를 같은 길이의 출력 시퀀스에 매핑 할 수 있다.
현재까지 거의 대부분의 딥러닝 사용자들에게 sequence modeling = RNN처럼 여겨져왔다.
Sequential model : Sequence Model이란, 연속적인 입력(Sequential Input)으로부터 연속적인 출력(Sequential Output)을 생성하는 모델이다. 예를 들어, 챗봇(Chatbot)과 기계 번역(Machine Translation)이 대표적인 예인데,챗봇(Chatbot)은 입력 시퀀스와 출력 시퀀스를 질문과 대답으로 구성한것이며기계 번역(Machine Translation)은 입력 시퀀스와 출력 시퀀스를 입력 문장과 번역 문장으로 구성한 것이다.
그러나, 최근 연구 결과는 CNN으로 audio, machine translation 같은 sequence modeling task에서 RNN을 앞설 수 있다고 말한다.
Paper: An Empirical Evaluation of Generic Convolutional and Recurrent Networks for sequence Modeling
논문에서의 결과는 TCN 아키텍쳐가 다양한 task에서 기존 lstm 같은 recurrent based model을 앞섰고, 또한 longer effective memory(장기 기억 능력)을 입증했다.
RNN계열의 특징은 네트워크의 가중치를 반복적으로 사용해서 시간순서를 모델링하는 것이다. 그러나 여기서 문제로, RNN은 가중치를 반복적으로 호출하기 때문에 뒷부분의 결과를 내기 위해서는 반드시의 앞의 결과가 나올때까지 대기해야 한다. 또한 매 층 마다 같은 타임 스텝을 이용해야 하기 때문에 시야가 고정적이라는 단점도 갖고 있다. 물론 dilated RNN같은 모델이 제안되었지만 여전히 stacked RNN구조에서 dilation을 다양하게 섞을 수는 없다. TCN(Temporal Convolutional Network)은 이런 RNN의 단점을 해결하고자 등장한 모델로 dialted convolution을 이용해 시계열 정보를 처리하는 모델이다.
2. TCN의 종류
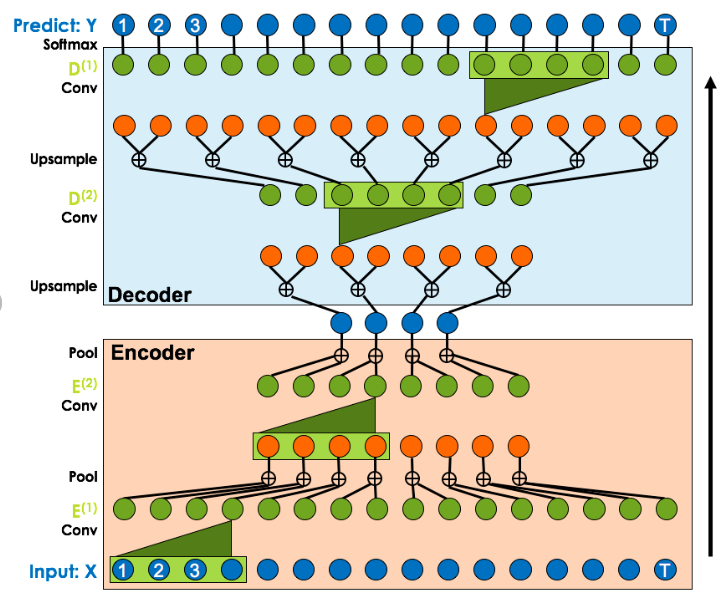
(1) Encoder-Decoder TCN
Encoding단계를 포함하기 위한 1차원 causal convolution과 pooling layer과의 조합, decoding 단계를 구성하는 일련의 upsampling 및 1차원 causal convolution layer를 포함한다.
이 모델의 convolution layer층은 확장되지 않지만 여전히 TCN층으로 간주된다.
(2) Dilated TCN
Causal convolution을 사용하는 모델이다.
A. Dilated Convolution란?
Dilated Convolution은 간단히 말해, 기존 convolution필터가 수용하는 픽셀 사이에 간격을 둔 형태이다.
입력 픽셀 수는 동일하지만, 더 넓은 범위에 대한 입력을 수용할 수 있게 된다.
Convolution(합성곱) : 합성곱 연산은 Conv-ReLU중 Conv계층에서 일어나는 연산으로 이미지 처리에서 말하는 필터 연산에 해당된다. 합성곱은 입력 데이터에 필터를 일정한 간격으로 이동하며 단일 곱셈-누산을 한다. 필터는 커널이라고 부르기로 하며, 가중치에 해당된다.
필터 연산이 끝나면 1X1 크기의 편향이 모든 원소에 더해진다. 편향의 크기는 항상 1X1이다.
즉, Convolution layer에 또 다른 파라미터인 dilation rate를 도입했다.
Dilation rate는 커널 사이의 간격을 정의하는데, dilation rate가 2인 3x3 kernel은 9개의 파라미터를 사용하면서, 5x5 kernel과 동일한 시야를 가진다.
2D convolution, 3 kernel, 2 dilation rate, no padding
Dilated convolution 은 특히 real-time segmentation 분야에서 주로 사용된다.
넓은 view 가 필요하고, 여러 컨볼루션이나 큰 커널을 사용할 여유가 없을 때 사용한다.
즉, 적은 계산 비용으로 Receptive Field 를 늘리는 방법이라고 할 수 있다.
이 Dilated convolution 은 필터 내부에 zero padding 을 추가해서 강제로 Receptive Field 를 늘리게 되는데, 위 그림에서 진한 파란색 부분만 weight 가 있고 나머지 부분은 0으로 채워지게 된다.
이 Receptive Field 는 필터가 한번 보는 영역으로 사진의 Feature 를 파악하고, 추출하기 위해서는 은 Receptive Field 를 사용하는 것이 좋다. dimension 손실이 적고, 대부분의 weight 가 0 이기 때문에 연산의 효율이 좋다.
공간적 특징을 유지하는 Segmentation 에서 주로 사용되는 이유이다.
B. Causal dilated convolution예제
Dilation : 같은 filter size로 더 넓은 영역을 볼 수 있게 팽장한 것 Stride : 보폭의 의미로 필터 적용 간격 Padding : 주변에 특정 값을 채우는 것
5) Dilation rate = 2, Kernel = 2, stride = 1, No zero padding
3. TCN의 구조
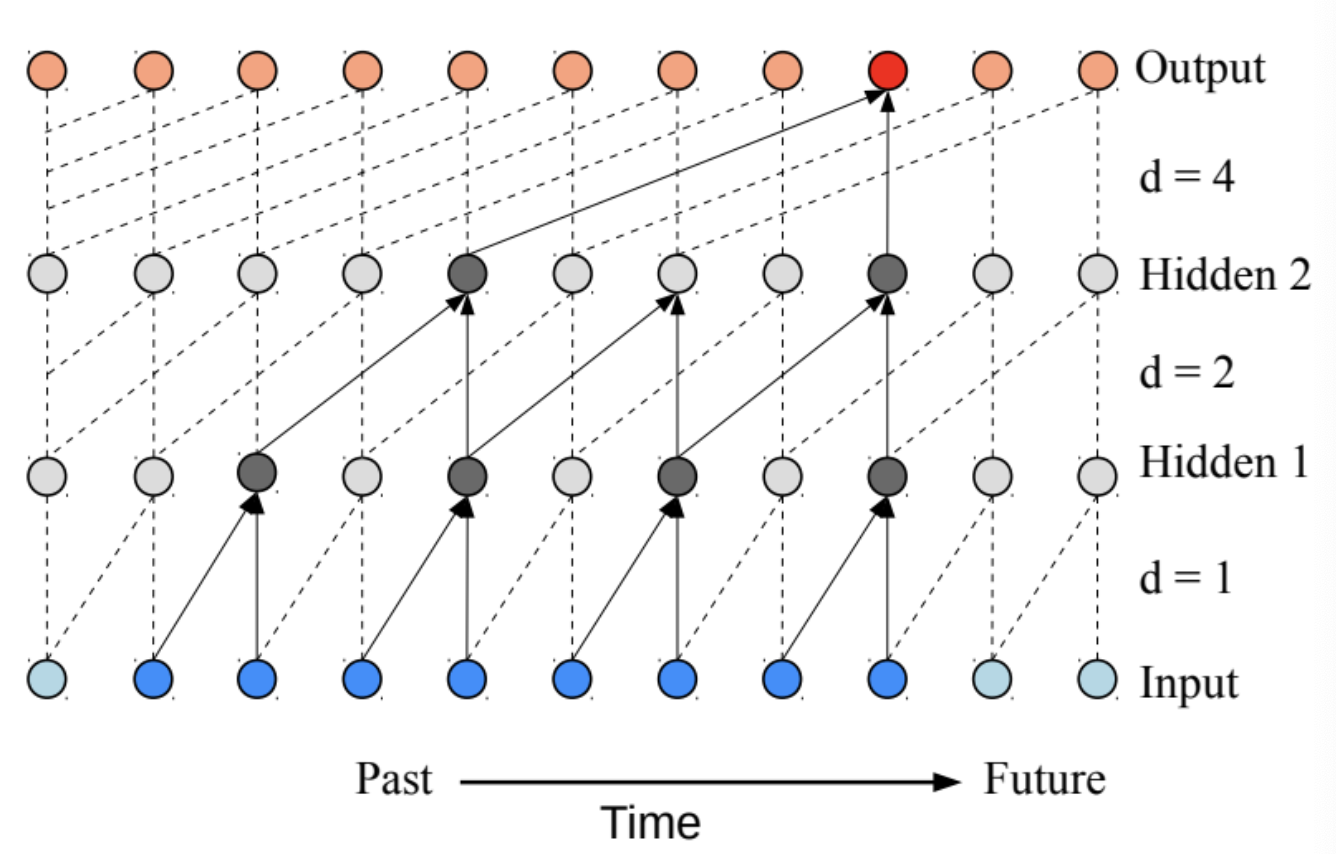
위 그림에서 시간은 왼쪽에서 오른쪽으로 흐르고 층은 아래에서 위로 쌓인다. 층이 깊어질수록 dilation이 점점 커지는 것을 확인할 수 있다.
층이 깊어질수록 dilation을 크게하는 이유는 입력층에 가까울 수록 local information이 중요하고 층이 깊어짐에 따라 점점 temporal information, 즉 순서정보를 학습하기 위함이다.
Simple causal convolution을 생각하면 과거 정보가 linear하게 filter수만큼 증가하게 된다. 이는 긴 정보를 저장하기 어려운 단점을 가지고 있어서 dilated convolution을 사용한다.
4. TCN의 장단점
(1) 장점
A. Parallelism(병렬 계산)
TCN은 GPU를 이용한 훈련에 적합하다. 특히 Convolution layer이 많은 행렬 연산은 그래픽 처리 과정의 일부인 행렬 계산을 수행하도록 구성된 GPU의 구조에 적합하기 때문이다. 이로 인해 TCN은 RNN보다 훨씬 빠르게 훈련할 수 있다. 즉, 대량의 데이터 처리시 이점을 가진다.
예를들어, RNN cell을 생각해보면 전 시점에 대하여 출력 값이 나와야지 다음 시점에 대한 출력 값을 계산할 수 있다. (전 state의 hidden + input이 넘어와야 계산이 가능하다.) 결국 병렬 처리가 I/O의 시간 차 이외에는 동시에 불가능하다. 하지만 TCN은 전 시점에 대한 출력 값이 다음시점에 필수 요소가 아니기 때문에 구조적을 병렬처리가 가능하다.
B. Flexible receptive field size(유연성)
TCN은 다양한 도메인에 쉽게 적응할 수 있도록 입력 크기, 필터 크기, Dilation rate 증가, 더 많은 층 쌓기 등을 변경할 수 있다. 즉, 수용 필드 크기(receptive field size; 영향 받는 범위)를 여러가지 방법으로 변경이 가능하다.
위와 같은 이유로 TCN은 모델의 메모리 크기를 유동적 제어가 가능하다.
하지만 장점이자 단점이 될 수 있는 부분은 hyper parameter의 자유도가 높아지는 것이기 때문에 best hyper parameter를 찾는 것이 이슈가 될 수 있다.
예를들어, high level layer 혹은 큰 dilation사용시 어떤 것이 같은 수용필드에서 더 좋은 효과가 일어날지 사전에 알 수 없다.
C. Stable gradients(일관된 그래디언트)
반복적인 RNN cell 구조와 달릴 TCN은 이전 시점의 부분 그레디언트(local gradient)가 필요조건이 아니기 때문에backpropagation 구조가 다르다. 즉, TCN은 convolution layer로 구성되기 때문에 RNN과는 다르게 backpropagation되므로 모든 gradient가 저장된다.
RNN은 gradient가 폭발(exploding)이나 gradient 소실(vanishing)이라 부르는 문제를 가지고 있는데, 계산된 gradient가 매우 크거나 작아서 재조정된 가중치가 너무 극단적으로 변경되거나 상대적으로 거의 변화가 없는 경우가 있다. 이를 해결하기 위해 LSTM, GRU, HF-RNN과 같은 RNN이 개발되었다.
Back Propagation(역전파) https://wikidocs.net/37406
D. Low memory requirement for training
Sequence가 길다고 가정하면, RNN 계열의 경우 각 시퀀스에 부분적인 게이트 결과물을 모두 저장하기 위하여 메모리 사용율이 올라간다. 따라서 RNN계열이 TCN보다 더 많은 곱셈 연산이 필요하므로 비교적 메모리 요구량이 더 크다.
TCN의 경우에는 convolution filter가 모두 공유되며 backpropagation(역전파) 경로는 네트워크 깊이에만 의존적이 된다. 상대적으로 TCN은 모두 각자의 필터를 공유하는 여러 층으로 구성되기 때문에 비교적 간단하기에, 장.단기 메모리에 비해 TCN은 메모리 사용량 측면에서 훨씬 가볍다.
E. Variable length inputs
RNN처럼 TCN도 1D conv filter를 사용하면서 각 시퀀스를 보기 때문에 입력 길이에 자유롭다.
(2) 단점
A. Data storage during evaluation(평가 모드 중 메모리 사용량)
학습된 RNN모델이 예측 할 때를 생각해 보면 반복적으로 Cell에서 나오는 전 시점의 게이트 값들이 더 이전시점들을 반영하는 값이다. 즉, Hidden state vector를 통해 학습된 모든 내용을 요약해 유지하므로 예측을 생성하기 위해서는 입력 Xt만 알면 된다. 따라서 t시점의 예측을 위해서는 t-1시점의 게이트 값 이외에는 모두 메모리에서 휘발성으로 삭제될 수 있다.
반면에 TCN, 즉 convolution 계열은 모든 시퀀스에 대해 결과값을 받아야 한다. 따라서 테스트 할 때의 RNN처럼 시점 단위로 휘발성을 사용하지 못하고 현재 시점까지의 시퀀스 전체가 필요하기 때문에 레이어 단위로만 휘발성으로 사용 가능하다.
B. Potential parameter change for a transfer of domain(전이 학습의 문제)
Transfer learning(전이학습) : 모델이 하나의 특정 작업(예: 차량 분류)에 대해 훈련을 받은 후 마지막 층을 꺼내 완전히 재교육해 모델을 새로운 분류 작업(예: 동물 분류)에 사용할 수 있도록 하는 것을 말한다. TCN에서는 모델은 예측을 하기 위해 다양한 수준의 시퀀스 이력을 기억할 수 있다. 모델이 예측을 위해 훨씬 더 많거나 적은 이력을 사용해야 하는 경우에 이슈가 발생할 수 있고 모델이 제대로 성능을 내지 못할 수 있다.
Transfer learning을 한다고 가정해보면, 어떤 분야(M)에서는 작은 메모리(작은 dilation숫자, 작은 필터 사이즈)가 필요하지만 어떤 분야(N)에서는 큰 메모리(큰 dilation 숫자, 큰 필터 사이즈)가 필요할 수 있다. 만약(M->N)로 전이학습을 하면 성능이 불량 할 수 있다.